What exactly is ‘Momentum’ in SGD with Momentum?
Step by step implementation with animation for better understanding.

2.2 What is SGD with Momentum?
SGD with Momentum is one of the most used optimizers in DL. Both the idea and the implementation are simple. The trick is to use a portion of the previous update and that portion is a scalar called ‘Momentum’.
You can download the Jupyter Notebook from here.
Note —It is recommended that you have a look at the previous post.
This post is divided into 3 sections
- SGD with Momentum in 1 variable
- SGD with Momentum animation for 1 variable
- SGD with Momentum in multi-variable function
SGD with Momentum in 1 variable function
SGD with Momentum is a variant of SGD.
In this method, we use a portion of the previous update.
That portion is a scalar called ‘Momentum’ and the value is commonly taken as 0.9
Everything is similar to what we did in SGD except here we have to first initialize update = 0 and while calculating update we add a portion of the previous update, i.e., momentum * update
SO, SGD with Momentum algorithm in very simple language is as follows:
Step 1 - Set starting point and learning rate
Step 2 - Initialize update = 0 and momentum = 0.9
Step 3 - Initiate loop
Step 3.1 Calculate update = -learning_rate * gradient +
momentum * update
Step 3.2 add update to pointFirst, let us define the function and its derivative and we start from x = -1

import numpy as np
np.random.seed(42)def f(x): # function definition
return x - x**3def fdash(x): # function derivative definition
return 1 - 3*(x**2)

And now SGD with Momentum
point = -1 # step 1
learning_rate = 0.01momentum = 0.9 # step 2
update = 0for i in range(1000): # step 3
update = - learning_rate * fdash(point) + momentum * update
# step 3.1
point += update # step 3.2
point # Minima

See, how easy it is to implement SGD with Momentum in Python
SGD with Momentum Animation for better understanding
Everything thing is the same as what we did earlier for the animation of SGD. We will create a list to store starting point and updated points in it and will use the iᵗʰ index value for iᵗʰ frame of the animation.
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from matplotlib.animation import PillowWriterpoint_sgd_momentum = [-1] # initiating list with
# starting point in itpoint = -1 # step 1
learning_rate = 0.01momentum = 0.9 # step 2
update = 0for i in range(1000): # step 3
update = momentum * update - learning_rate * fdash(point)
# step 3.1
point += update # step 3.2
point_sgd_momentum.append(point) # adding updated point
# to the list point # Minima

We will do some settings for our graph for the animation. You can change them if you want something different.
plt.rcParams.update({'font.size': 22})fig = plt.figure(dpi = 100)fig.set_figheight(10.80)
fig.set_figwidth(19.20)x_ = np.linspace(-5, 5, 10000)
y_ = f(x_)ax = plt.axes()
ax.plot(x_, y_)
ax.grid(alpha = 0.5)
ax.set_xlim(-5, 5)
ax.set_ylim(-5, 5)
ax.set_xlabel('x')
ax.set_ylabel('y', rotation = 0)
ax.scatter(-1, f(-1), color = 'red')
ax.hlines(f(-0.5773502691896256), -5, 5, linestyles = 'dashed', alpha = 0.5)ax.set_title('SGD with Momentum, learning_rate = 0.01')


Now we will animate the SGD with Momentum optimizer.
def animate(i):
ax.clear()
ax.plot(x_, y_)
ax.grid(alpha = 0.5)
ax.set_xlim(-5, 5)
ax.set_ylim(-5, 5)
ax.set_xlabel('x')
ax.set_ylabel('y', rotation = 0)
ax.hlines(f(-0.5773502691896256), -5, 5, linestyles = 'dashed', alpha = 0.5)
ax.set_title('SGD with Momentum, learning_rate = 0.01')
ax.scatter(point_sgd_momentum[i], f(point_sgd_momentum[i]), color = 'red')The last line in the code snippet above is using the iᵗʰ index value from the list for iᵗʰ frame in the animation.
anim = animation.FuncAnimation(fig, animate, frames = 200, interval = 20)anim.save('2.2 SGD with Momentum.gif')
We are creating an animation that only has 200 frames and the gif is at 50 fps or frame interval is 20 ms.
It is to be noted that in less than 200 iterations we have reached the minima.

SGD with Momentum in multi-variable function (2 variables right now)
Everything is the same, we only have to initialize point (1, 0) and update = 0 but with shape (2, 1) and replace fdash(point) with gradient(point).
But first, let us define the function, its partial derivatives and, gradient array

We know that Minima for this function is at (2, -1)
and we will start from (1, 0)
The partial derivatives are
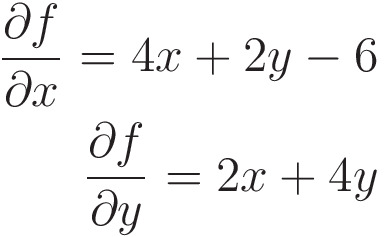
def f(x, y): # function
return 2*(x**2) + 2*x*y + 2*(y**2) - 6*x # definitiondef fdash_x(x, y): # partial derivative
return 4*x + 2*y - 6 # w.r.t xdef fdash_y(x, y): # partial derivative
return 2*x + 4*y # w.r.t ydef gradient(point):
return np.array([[ fdash_x(point[0][0], point[1][0]) ],
[ fdash_y(point[0][0], point[1][0]) ]], dtype = np.float64) # gradients

Now the steps for SGD with Momentum in 2 variables
point = np.array([[ 1 ], # step 1
[ 0 ]], dtype = np.float64)learning_rate = 0.01momentum = 0.9 # step 2
update = np.array([[ 0 ],
[ 0 ]], dtype = np.float64)for i in range(1000): # step 3
update = - learning_rate * gradient(point) + momentum * update
# step 3.1
point += update # step 3.2
point # Minima

I hope now you understand SGD with Momentum.
Now as a bonus let us take a look at how SGD with Momentum is better than SGD.
We have a function

and this is the graph for the function

Now if we start at x = 0.75 with learning rate = 0.01 and use SGD optimizer, then we will reach the local minima at x = 0

But if we start from x = 0.75 with learning rate = 0.01 and use SGD with Momentum optimizers with momentum = 0.9, then we will reach the global minima at x = -1.64

You only have to change f(x), fdash(x), and the starting point with few graph settings.
Watch the video on youtube and subscribe to the channel for videos and posts like this.
Every slide is 3 seconds long and without sound. You may pause the video whenever you like.
You may put on some music too if you like.
The video is basically everything in the post only in slides.
Many thanks for your support and feedback.
If you like this course, then you can support me at


It would mean a lot to me.
Continue to the next post — 2.3 SGD with Nesterov acceleration.
